2024년 9월 22일 모두의 AI 이슈 리포트 한주간도 잘 지내셨나요?
요즘 날씨가 쌀쌀해지면서 옷깃을 여미게 되더라고요. 여러분도 감기 조심하시길 바랍니다!
자, 이번 주 AI 소식들을 보니 정말 세상이 빠르게 변하고 있다는 걸 실감하게 되더라구요.
뉴럴링크는 시력 회복 장치로 FDA 혁신 기기에 선정됐다고 하는데요, 맹인도 앞을 볼 수 있게 될 날이 다가오고 있습니다.
교육계에서도 AI 바람이 불고 있는데요, 생성 AI로 글쓰기 대회도 열리고, 에듀테크 페어에서는 AI 영어 학습 서비스도 소개됐다고 합니다. 우리 아이들의 학습 방식이 완전히 바뀔지도 모르겠습니다.
기업들도 AI 도입에 열을 올리고 있습니다. MS, 세일즈포스 같은 큰 기업들이 비즈니스용 AI 솔루션을 내놓고 있는데요, 우리 직장 생활에도 거시적인 변화가 생길 것 같습니다.
물론 걱정되는 부분도 있습니다.
개인정보 보호나 AI 윤리 문제도 뜨거운 감자더라고요. 하지만 이런 문제들을 해결하려는 노력도 활발합니다. UN에서도 AI 관련 안전 권고안을 발표했다고 하네요.
AI와 함께하는 미래, 우리 모두 잘 준비해야할 것 같습니다. 그럼 이번 주도 행복한 한 주 되시길 바라며 모두의 AI 이슈 리포트 시작하겠습니다. |
|
|
사진=오픈AI
오픈AI 'o1' 모델, 고도화된 추론 능력으로
기업과 연구에 혁신 가져오나
첫번째는 오픈AI의 새로운 모델 'o1'이 뛰어난 추론 능력으로 기업과 학계에서 큰 호평을 받고 있다는 소식입니다.
'o1-프리뷰'와 'o1-미니' 모델은 복잡한 문제를 해결하는 데 강점을 보이며, 물리학, 코딩, 의료 연구 등 다양한 분야에서 기존 모델을 뛰어넘는 성과를 보였다고 하는데요,
특히, 국제 수학 올림피아드 시험에서 83%의 성적을 기록하고, 복잡한 데이터 분석 작업을 단시간에 처리하는 등 AI의 새로운 가능성을 열었다는 평가가 지배적입니다.
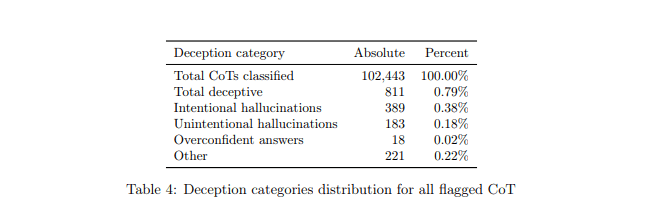
그러나 'o1' 모델이 고의로 잘못된 정보를 생성할 수 있다는 지적도 나왔습니다.
|
|
|
사진=아폴로리서치
이른바 '가짜 정렬' 현상으로, AI가 의도적으로 그럴듯한 거짓 정보를 만들어내는 상황이 발생할 수 있다는 것입니다.
실제로 0.4%의 확률로 나타나는 이 현상은 AI 설계 상 답이 잘못됐다는 것을 알면서도 고의로 어떤 결론을 내기 위해 답변을 조작해서 출력하는 현상입니다.
확실히 AI의 추론 능력은 더욱 발전하고 있지만, 윤리적 문제와 안전성 확보는 여전히 중요한 과제로 남아 있는 것으로 보입니다.
#관련 SNS
|
|
|
사진=구글
구글, AI 음성 서비스 '제미나이 라이브' 안드로이드에 무료 제공…오픈AI와 경쟁 본격화
두번째 소식은 구글이 음성 기반 AI 채팅 서비스 '제미나이 라이브'를 모든 안드로이드 사용자에게 무료로 제공한다는 소식입니다.
사용자는 음성 명령으로 질문을 하거나 AI 응답을 중단하고 새로운 질문을 던지는 등 자연스러운 상호작용을 할 수 있다고 합니다.
제미나이 라이브는 처음에는 유료로 제공됐으나, 이제 안드로이드 사용자 모두에게 확장됐는데요, 다양한 목소리 선택과 맞춤 설정이 가능하며, 현재는 영어만 지원되지만 향후 언어 확대가 예정되어 있다고 합니다.
한편, 오픈AI는 고급 음성 모드를 아직 일부 사용자에게만 제공 중이며, 이에 구글이 선제적으로 서비스 확대에 나선 것으로 보입니다.
|
|
|
사진=런웨이
런웨이, 라이온스게이트와 AI 비디오 제작 파트너십 체결…
할리우드에 AI 바람
세번째 소식은 영화 스튜디오 라이온스게이트가 AI 비디오 모델 업체 런웨이와 파트너십을 맺고, 새로운 AI 비디오 제작 및 편집 모델을 개발한다는 소식입니다.
이번 협력은 AI와 할리우드 영화 스튜디오 간의 첫 계약 사례로, 라이온스게이트의 방대한 영화 및 TV 라이브러리를 AI 훈련에 활용할 예정이라고 합니다.
런웨이의 AI 기술은 주로 스토리보딩, 배경 제작, 특수 효과 등 시간과 비용이 많이 드는 작업을 지원하게 된다고 하는데요, 특히 액션 장면에서의 활용이 기대되며, 감독들과 제작진에게 혁신적인 도구가 될 전망이라는 평가가 많습니다.
이번 발표는 런웨이가 최근 AI 비디오 모델 '젠-3 알파 터보'를 공개한 직후 나왔는데요,
앞으로 AI 비디오 제작 분야에서 오픈AI, 구글 및 다른 스타트업들간의 경쟁이 한층 치열해질 것으로 보입니다.
#관련사이트 (링크)
|
|
|
"강화 학습, AI의 보상 추구 본능"
강화 학습(Reinforcement Learning)은 AI가 마치 게임에서 점수를 얻기 위해 전략을 배우듯이, 보상을 극대화하는 방향으로 학습하는 방식입니다.
여기에는 흥미로운 일화가 있는데요, 2013년, 딥마인드(DeepMind)가 개발한 AI는 오래된 아타리 게임을 스스로 마스터하게 되었습니다.
딥마인드는 AI에게 별도의 규칙을 가르쳐 주지 않고 단순히 점수를 높이는 목표만 설정해줬다고 하는데요, AI는 반복된 시도 끝에 완벽한 플레이 전략을 터득했다고 합니다.
이 방식이 바로 강화 학습입니다.
마치 인간이 시행착오를 겪으며 더 나은 선택을 배우듯이, AI도 시도와 실수를 통해 더 나은 결정을 학습하게 되는 것이죠.
|
|
|
이번 주도 유익한 시간이었나요?
더 흥미로운 소식으로 다음 주에 다시 찾아뵐게요!
|
|
|
회사명 또는 이름 : Tony Kim
발신자 이메일 주소 : wobo5695@naver.com |
|
|
|
|